Flink Window机制与Timer
问题分析从实际场景出发流处理面临的问题流处理中的概念时间窗口WindowFlink中的window设置EventTimewindow的生命周期乱序数据-water mark&latenessTriggerEventTimeTriggerContinuousEventTimeTriggerEvictors代码示例总结缓存与定时Windowed stream 操作Key-window and non-key windowWindow操作的几个问题1. 实时性2. sink触发频繁3. 大窗口Timer4 characteristics of Timers to keep in mind对应源码Process time的实现机制Event time的实现机制参考
问题分析
从实际场景出发
场景:实时统计人流量总数,可以根据点位按时段统计,可以是实时刷新,也可以是定期查询前一段时间。
流处理面临的问题
通常流处理框架,就是实时计算,数据源源不断输入,实时输出结果,所以面临以下几个问题:
- 窗口的划分
- 数据乱序、延迟到达
- 何时触发窗口计算
- 计算状态的存储和过期
流处理中的概念
时间
通常流处理框架都有以下几个时间概念
- Event Time:事件时间,从事件的消息体中提取时间
- Ingestion Time:到达时间,消息到达流处理器的时间(kafka-stream存在)
- Process Time:消息被处理的时间
前两者都可能存在乱序的情况(out of order),process time可以保证时间顺序是递增的。
窗口Window
主要有以下几种类型的窗口:
- Tumbling windows 翻转窗口:固定大小,窗口不重叠、窗口之间没有间隔
- Hopping windows
跳跃时间窗口:由窗口大小和滑动间隔确定,例如窗口大小为5000,间隔(滑动)3000的窗口,可以得到
[0;5000),[3000;8000),..
- Sliding windows 滑动时间窗口:窗口大小的计算和Hopping windows一样,但是是将每次窗口数据发生变化的时候作为窗口的起始。动态窗口起点,固定窗口大小,因此每个窗口都至少有一个元素
- Session window 基于事件的,动态大小,例如间隔超出N(称为gap)没有新数据,之后的数据就是一个新session
窗口可以是时间驱动的,即Time window,组合窗口类型可以得到翻转时间窗口和滑动时间窗口
也可以是基于数据的Count Window,当窗口数量达到一定值时关闭,可以得到翻转计数窗口和滑动计数窗口
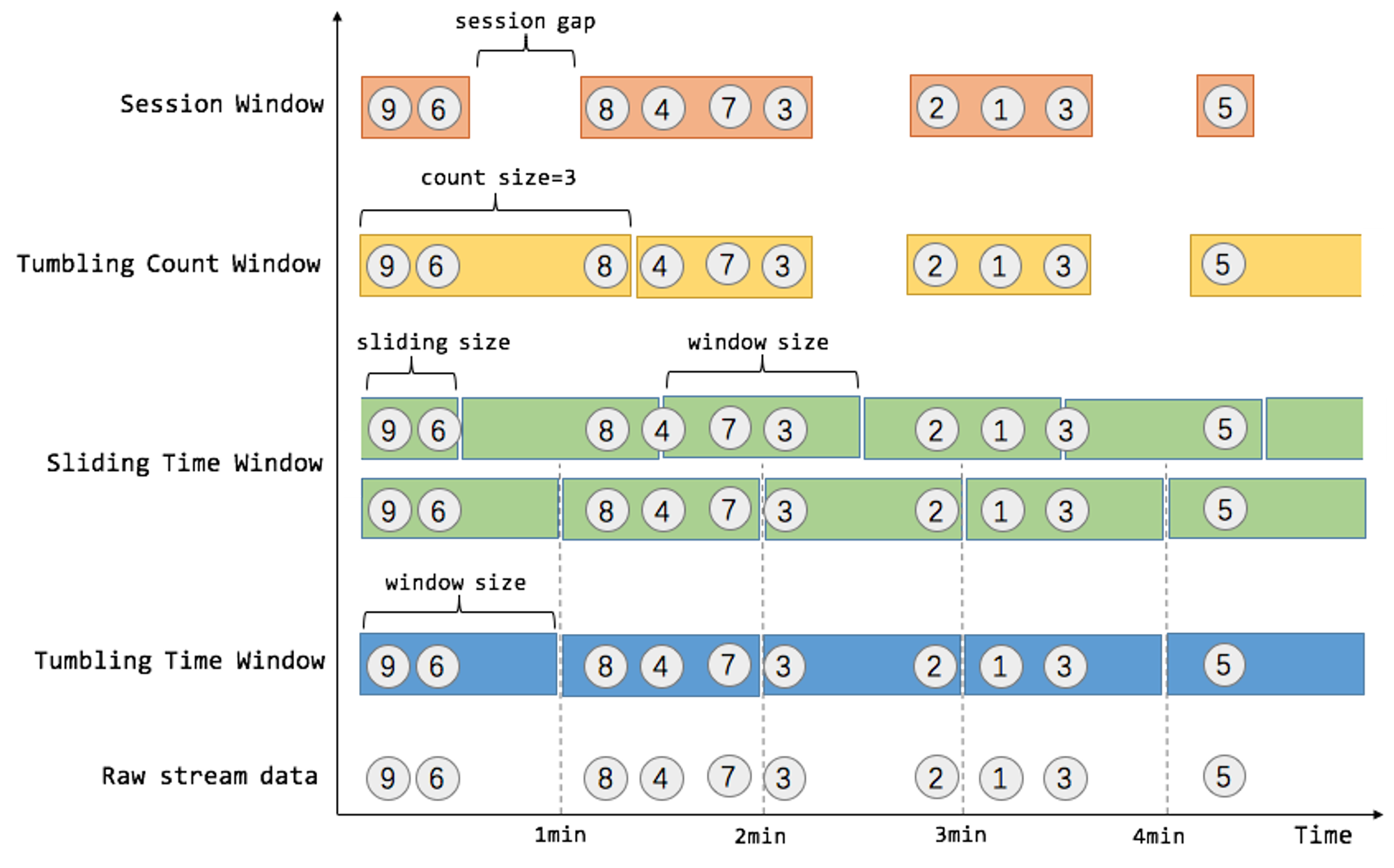
Flink中的window
Flink支持以下几种类型的窗口
- Tumbling Time Window
- Sliding Time Window
- Tumbling Count Window
- Sliding Count Window
- Session Window
设置EventTime
flink 通过
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)来设定流处理中window使用的时间类型(主要是用于划分window和管理window的生命周期,包括创建、销毁)在flink流处理的Source中或者处理window之前,都可以通过调用
assignTimestampsAndWatermarks来指定如何从消息中获得当前事件时间(watermark在后文讲)window的生命周期
- 创建:当第一个元素落入到window中的时候被创建
- 触发:根据配置的trigger确定
- 销毁: 根据配置的时间是event time还是process time,当获得到的当前event/process time, 大于窗口的endtime+watermark+lateness时候,窗口被销毁。
如果持续一段时间没有数据,也就不能获得最新的时间,则最后几个窗口会一直保持开启。
a window is created as soon as the first element that should belong to this window arrives, and the window is completely removed when the time (event or processing time) passes its end timestamp plus the user-specified allowed lateness(see Allowed Lateness)
乱序数据-water mark&lateness
对于乱序数据怎么办呢?一旦出现乱序,如果只根据 eventTime 决定 window 的运行,我们不能明确数据是否全部到位,又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
watermark,直译为水位线,表示eventTime小于watermark的事件已经全部落入到相应的窗口中。例如流中一个事件A,其event_time=6,watermark=3,则表示第3s之前的数据都已经落入窗口。窗口是否关闭将依赖于计算出的watermark值和窗口end进行比较。
例如一个时间窗口是[0-5),watermark=event_time-3,那么一个6s的事件,它的watermark就应该是3,一个7s的watermark是4s,这两个都落在窗口中
在flink流处理的Source中或者处理window之前,都可以通过调用
assignTimestampsAndWatermarks来指定如何从消息中获得当前事件时间和获得当前事件的watermark。可以直接扩展几个预定义的类实现。默认watermark是0,也即watermark时间等于事件时间。watermark不是对每一条数据都会生成的,默认配置每200ms生成一次,可以通过env.getConfig().setAutoWatermarkInterval()配置产生间隔。此外,flink还允许在流处理window后设定
allow lateness来指定一个最晚的时间,没有超过这个最晚时间,window还是未销毁,可以触发计算。(默认的lateness也是0)那么watermark和lateness区别在哪里呢?
这个主要是配合trigger的行为,默认的EventTimeTrigger,之前的元素是不触发window计算的,在watermark达到window end的时候,会触发一次window计算;之后的每一个迟到的元素进入窗口,都会触发一次window计算。所以watermark是保证大部分元素的时间落在windowend+watermark的区间内,减少window计算的触发次数。如果是其他trigger方式,watermark的意义不大。窗口触发计算时,会将窗口数据传给后续的处理过程处理。
如上所述,EventTimeTrigger等一些默认的trigger,在watermark时间达到window end之前是不会触发的,如果事件有一段时间暂停了没有新元素,或者窗口期很长,则导致一直没有触发计算获得结果,延迟比较大,这时候可以使用ContinuousProcessingTimeTrigger。
对于延迟的数据,也可以定时可以把它揪出来处理。通过对WindowedStream设置sideOutputLateData,之后从WindowedStream处理的结果SingleOutputStreamOperator的getSideOutput(OutputTag)方法得到被丢弃的数据(这个是需要定时任务去处理)
只有所有的线程的最小watermark都满足watermark 时间 >= window_end_time时,触发历史窗才会执行。
Trigger
窗口何时计算,仅取决于trigger的定义。
可以自己扩展trigger,实现何时触发窗口计算,如果不设置,flink会根据窗口类型自动设定。
The trigger interface has five methods that allow a
Trigger to react to different events:- The
onElement()method is called for each element that is added to a window.
- The
onEventTime()method is called when a registered event-time timer fires.
- The
onProcessingTime()method is called when a registered processing-time timer fires.
- The
onMerge()method is relevant for stateful triggers and merges the states of two triggers when their corresponding windows merge, e.g. when using session windows.
- Finally the
clear()method performs any action needed upon removal of the corresponding window.
Two things to notice about the above methods are:
- The first three decide how to act on their invocation event by returning a
TriggerResult. The action can be one of the following: CONTINUE: do nothing,FIRE: trigger the computation,PURGE: clear the elements in the window, andFIRE_AND_PURGE: trigger the computation and clear the elements in the window afterwards.
- Any of these methods can be used to register processing- or event-time timers for future actions.
此外,Trigger的Context是可以配置state的,这里的ContinuousEventTimeTrigger就使用state存储了触发时间信息。更新信息参考flink文档:work with state.同样,针对keyedStream的process方法也支持状态存储。
通过设置state,可以清除掉之前已经计算过的窗口数据,减少大窗口的window缓存占用,这个状态也是会传递到后续的处理中。示例代码如下
//每次触发后清除状态 .trigger(PurgingTrigger.of(ContinuousProcessingTimeTrigger.of(Time.seconds(30)))) .process(new ProcessWindowFunction<ObjectNode, Tuple3<TimeWindow,String,Long>, String, TimeWindow>() { private ValueStateDescriptor<Long> countState =new ValueStateDescriptor<Long>("cont-num",Long.class); @Override public void process(String s, Context context, Iterable<ObjectNode> elements, Collector<Tuple3<TimeWindow,String,Long>> out) throws Exception { //called every time windowed calculate was triggered long count=0; for (ObjectNode x :elements) { count++; } //为每个窗口创建了一个状态 //之前每次都会pure //这种操作下,当pure后,如果没有新数据,也不会再触发该process //如下下面的redis sink有缓存,缓存就不会更新到redis啦。所以sink要加定时器 Long origin=context.windowState().getState(countState).value(); if(origin==null){ origin=0L; } count+=origin; context.windowState().getState(countState).update(count); out.collect(new Tuple3<>(context.window(),s,count)); } }) .addSink(new RedisCountSink());
EventTimeTrigger
@Override public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception { if (window.maxTimestamp() <= ctx.getCurrentWatermark()) { // if the watermark is already past the window fire immediately //当前watermark已经超过window end时间了,立即触发(对应lateness内的迟到元素) return TriggerResult.FIRE; } else { //注册一个定时器 ctx.registerEventTimeTimer(window.maxTimestamp()); return TriggerResult.CONTINUE; } } @Override public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) { return time == window.maxTimestamp() ? TriggerResult.FIRE : TriggerResult.CONTINUE; }
ContinuousEventTimeTrigger
private ContinuousEventTimeTrigger(long interval) { this.interval = interval; } @Override public TriggerResult onElement(Object element, long timestamp, W window, TriggerContext ctx) throws Exception { if (window.maxTimestamp() <= ctx.getCurrentWatermark()) { // if the watermark is already past the window fire immediately return TriggerResult.FIRE; } else { ctx.registerEventTimeTimer(window.maxTimestamp()); } ReducingState<Long> fireTimestamp = ctx.getPartitionedState(stateDesc); if (fireTimestamp.get() == null) { //没有注册过定时器 long start = timestamp - (timestamp % interval); long nextFireTimestamp = start + interval; //注册下一个触发时间 ctx.registerEventTimeTimer(nextFireTimestamp); fireTimestamp.add(nextFireTimestamp); } return TriggerResult.CONTINUE; } @Override public TriggerResult onEventTime(long time, W window, TriggerContext ctx) throws Exception { //这里传入的time,注释是说就是触发时间 if (time == window.maxTimestamp()){ //达到watarmark,触发 return TriggerResult.FIRE; } ReducingState<Long> fireTimestampState = ctx.getPartitionedState(stateDesc); Long fireTimestamp = fireTimestampState.get(); if (fireTimestamp != null && fireTimestamp == time) { //达到之前注册的定时器,触发 fireTimestampState.clear(); fireTimestampState.add(time + interval); ctx.registerEventTimeTimer(time + interval); return TriggerResult.FIRE; } return TriggerResult.CONTINUE; }
ContinuousEventTimeTrigger的触发也是针对
事件时间定期触发,如果是元素流会停止一段时间或者需要及时获取结果,应该采用ContinuousProcessingTimeTrigger。使用
trigger(ContinuousEventTimeTrigger.of(Time.seconds(30))),可以提前计算,也即不需要等待达到watermark触发条件,只要当前时间达到开始时间加一个值,就触发计算了,这个时间也是从eventtime得到的。不能解决没有新元素到达且没有到watermark的情况,使用ContinuousProcessingTimeTrigger.of(Time.seconds(30))可以根据实际时间触发计算。对于OnEventTime或者OnProcessTime,出入的time参数分别是eventtime或者processtime。如果一直没有后续数据到来,窗口就不会关闭(窗口关闭还是根据eventTime决定的)。
trigger注册的时间,是被内部的一个
InternalTimerService处理,可参考后文说明,process timer是直接jdk库注册到指定时间执行,event timer好像是每个事件到达都会判断watermark与队列的时间比较确定是否触发。已经注册的时间小于当前watermark/processtime的window都会被回调。
更多参见后文【Timer】
Evictors
保留指定长度或者指定时间段内的窗口数据,剩余的数据会清除
可以指定在触发后,窗口处理前或处理后,进行清理数据。
The evictor has the ability to remove elements from a window after the trigger fires and before and/or after the window function is applied
代码示例
env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); //env.getConfig().setAutoWatermarkInterval(); env.enableCheckpointing(600000); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.setStateBackend(new RocksDBStateBackend("file:///flink/state/")); Properties properties = new Properties(); properties.setProperty("bootstrap.servers", kafkaServers); properties.setProperty("group.id", "vehicle-count"); FlinkKafkaConsumer<ObjectNode> consumer=new FlinkKafkaConsumer<ObjectNode>(dataTopic, new JSONKeyValueDeserializationSchema(true), properties); //设定如何提前事件时间,watermark设定为5分钟 consumer.assignTimestampsAndWatermarks(new KafkaTimestampExtractor(Time.minutes(5))); consumer.setStartFromEarliest(); DataStream<ObjectNode> stream = env.addSource(consumer); stream .filter(k->k.get("value").has("tollgateID")) .keyBy(map -> map.get("value").get("tollgateID").asText()) .timeWindow(Time.seconds(10)) .allowedLateness(Time.minutes(2)) .trigger(ContinuousProcessingTimeTrigger.of(Time.seconds(30))) .process(new ProcessWindowFunction<ObjectNode, Tuple3<TimeWindow,String,Long>, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<ObjectNode> elements, Collector<Tuple3<TimeWindow,String,Long>> out) throws Exception { //called every time windowed calculate was triggered //这里可以使用缓存状态,参见其他实例代码 long count=0; for (ObjectNode x :elements) { count++; } out.collect(new Tuple3<>(context.window(),s,count)); } }) .addSink(new RedisCountSink()); Executor executor= Executors.newFixedThreadPool(1); //env.execute()是阻塞方法 CompletableFuture<JobExecutionResult> future=CompletableFuture.supplyAsync(new Supplier<JobExecutionResult>() { @Override public JobExecutionResult get() { try { return env.execute(); } catch (Exception e) { e.printStackTrace(); return null; } } }, executor);
上面的process,可以换成map+sum的方式,map对每个元素变成Tupple,每个Tupple后面补个1,sum位置选择最后一位就可以了。之所以有这种考虑,因为ProcessFunction每次触发都要全部处理一遍,会更损耗性能和资源,这个可以参考文档对不同函数的说明
Flink uses a ReduceFunction to incrementally aggregate the elements of a window as they arrive 不会像pocess那样,每触发一次就要重新算一遍总数,使用其他函数,会增量提前计算好,等到Trigger.Fire时候再传递给reduce的下一步。 sum函数无法获得window信息了,可以自定义aggregate实现sum
总结
- 窗口分配器:就是决定着流入flink的数据,该属于哪个窗口。
.TimeWindow创建,源码都extends WindowAssigner
- 时间戳抽取器/watermark生成器:抽取时间戳并驱动着程序正常执行。assignTimestampsAndWatermarks()
- trigger:决定着数据啥时候落地。
缓存与定时
flink每个窗口触发计算时,都会把结果直接传给后续的processer,如果后面是存储到数据库、redis等,性能比较低,所以需要做批量处理。这里要考虑:
- 设定批量的限制,一批数据不要太大
- 需要有个定时功能,长期达不到批量最小值,也要执行入库
这里参考
StreamingFileSink的实现,其在open方法中得到了TimerService,然后扩展ProcessingTimeCallback,也可以监听save checkpoint。代码如下
private static class RedisCountSink extends RichSinkFunction<Tuple3<TimeWindow,String,Long>> implements ProcessingTimeCallback { private ConcurrentLinkedQueue<Tuple3<TimeWindow,String,Long>> cache; private transient StringRedisTemplate template; private final String sortedSetKey = "vehicle:stream:vehicle-count"; private long duration=30000; private ProcessingTimeService processingTimeService; @Override public void open(Configuration parameters) throws Exception { super.open(parameters); template = SpringUtils.getBean(StringRedisTemplate.class); cache=new ConcurrentLinkedQueue<>(); this.processingTimeService = ((StreamingRuntimeContext) getRuntimeContext()).getProcessingTimeService(); long currentProcessingTime = processingTimeService.getCurrentProcessingTime(); processingTimeService.registerTimer(currentProcessingTime + duration, this); } @Override public void invoke(Tuple3<TimeWindow,String,Long> value, Context context) throws Exception { cache.add(value); if(cache.size()>10000){ flush(); } } private void flush() { template.executePipelined((RedisCallback<Object>) redisConnection -> { StringRedisConnection stringCoon = (StringRedisConnection) redisConnection; while (!cache.isEmpty()) { Tuple3<TimeWindow,String,Long> data = cache.poll();// TimeWindow k = data.f0; long time = k.getStart(); System.out.println("consume "+data.f1); String key = sortedSetKey + ":" + time; stringCoon.zAdd(sortedSetKey, time, key); stringCoon.hSet(key, data.f1, data.f2.toString()); } return null; }); } @Override public void onProcessingTime(long timestamp) throws Exception { final long currentTime = processingTimeService.getCurrentProcessingTime(); flush(); processingTimeService.registerTimer(currentTime + duration, this); } }
还有就是,针对KeydStream,自定义ProcessFunction也支持注册定时器
private class CountProcess extends ProcessFunction<String,String>{ @Override public void processElement(String value, Context ctx, Collector<String> out) throws Exception { ctx.timerService().registerProcessingTimeTimer(1000); //这里ctx也支持存储临时的状态,可以利用之前存储的状态进行计算 } @Override public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception { } }
Windowed stream 操作
- reduce 操作是针对每个元素进行操作的,但是输出就丢失了window信息,但是也是按照window进行聚合的,输出到下一步的每个元素都是一个window的结果。
- aggregate 低级的聚合api,很多操作是基于这个操作实现的,可以同时进行增量聚合操作并将聚合的结果传递给processwindowfunction,可以保存window信息,并且聚合操作是针对每个窗口进行的。就是对每个窗口聚合完成直接传入参数中的processwindowfunction. sum,min,max函数等很多自带方法都是基于这个api实现的
虽然聚合操作是增量进行的,每个元素到达都会操作,但是传递给后续操作依然是由trigger控制的。
//在aggregate内求和,这个结果传给ProcessWindowFunction,然后带上window、key等信息直接传给后续的处理;aggregate内是增量的 //注意,使用aggregate的方法时,不能与Evictors一起工作 //aggregate也会被pure trigger清空缓存 .aggregate(new AggregateFunction<ObjectNode, Long, Long>() { @Override public Long createAccumulator() { return 0L; } @Override public Long add(ObjectNode value, Long accumulator) { return accumulator+value.get("num").asLong(); } @Override public Long getResult(Long accumulator) { return accumulator; } @Override public Long merge(Long a, Long b) { return a+b; } }, new ProcessWindowFunction<Long, Tuple3<TimeWindow,String,Long>, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<Long> elements, Collector<Tuple3<TimeWindow, String, Long>> out) throws Exception { for (Long count:elements) { out.collect(new Tuple3<>(context.window(),s,count)); } } })
Key-window and non-key window
针对keyed-stream创建的window,会充分利用多线程,不同的key分配到不同线程处理,默认线程是当前cpu核数的2倍,可以通过env设置。
但是non-key window只会有一个线程处理。
如果sink加了缓存,会每个线程都是独立的缓存,所以可能不需要考虑多线程操作,都是同步操作。 如果某个key更新数据,只会触发所在线程的window操作,其他线程不会刷新 所以很多<u>实例都是一个线程一个的</u>
Window操作的几个问题
1. 实时性
基于EventTime情况下,窗口不关闭,导致不能实时获得结果,可以使用ContinuousEventTimeTrigger,但是必须保证数据持续流入,如果流入的数据event time没有达到注册的event time,还是不会触发
这时可以换成ContinuousProcessTimeTrigger,这个是注册的系统时间定时,会定时触发,无论是否有数据流入
2. sink触发频繁
每个window的触发计算结果都会传入后续处理,如果后续是要存储数据库,当窗口过多时(例如很多key,每个key都有一个窗口),则会频繁的触发sink方法。
在sink处加一个缓存,在
open方法中初始化,同时获得定时器,注册timer,具体参见上文的【定时与缓存】一节。如果针对的是keyedStream后接的处理器,则可以直接注册定时器。
多个窗口都没有新数据时,哪个窗口有新数据传入,只会触发该窗口,对其他窗口没有影响的
3. 大窗口
如果需要统计比较长时间的窗口,例如1h,这时候窗口中的数据会比较多,全部存储在缓存中,如何处理?
- 方案1
使用processFunction,在processFunction中,使用
context.getWindowState创建一个状态存储,存储当前计算结果,然后使用PurgingTrigger在每次触发后清空windows
- 方案2 使用增量aggregate方法计算结果,配合puretrigger+状态存储。其实方案1每个window的数据只会被计算一次,所以该方案对比方案1没有什么区别。
- 方案3 方案1和2,如果在sink处加了缓存,没有新数据时,就不会触发sink,可以在window之前,把数据的非必要属性都删掉,大窗口的数据大小也就不会太大,然后使用aggregate方法增量计算加快每次触发计算时间,不pure窗口数据。
方案1参考上文Trigger的示例代码。
方案2参考上文aggregate的示例代码。
Timer
The onTimer(...) callback is called at different points in time depending on whether processing or event time is used to register the Timers in the first place. In particular:
When using processing time to register Timers in your Flink application, the onTimer(...) method is called when the clock time of the machine <u>reaches the timestamp of the timer.</u>
When using event time to register Timers in your Flink application, the onTimer(...) method is called when the operator’s <u>watermark reaches or exceeds the timestamp of the timer</u>.
Similar to the processElement(...)method, state access within the onTimer(...)callback is also scoped to the current key (i.e., the key for which the timer was registered for).
It is worth noting here that <u>both the onTimer(...) and processElement(...)calls are synchronized</u>, and thus it is safe to access state and modify it in both the onTimer(...)and processElement(...) methods.
4 characteristics of Timers to keep in mind
In this paragraph, we discuss the 4 basic characteristics of Timers in Apache Flink that you should keep in mind before using them. These are the following:
- Timers are registered on a KeyedStream.
Since timers are registered and fired per key, a KeyedStream is a prerequisite for any kind of operation and function using Timers in Apache Flink.
每个窗口包含的内容也是keydStream,所以在Trigger中可以为窗口注册Timer
- Timers are automatically deduplicated.
The TimerService deduplicates timers per key and timestamp, i.e., <u>there is at most one timer per key and timestamp</u>. If multiple timers are registered for the same timestamp, the onTimer() method will be called just once.(针对一个key,注册多次同一个时间的Timer,只会触发一次)
- Timers are checkpointed.
Timers are checkpointed by Flink, just like any other managed state. When restoring a job from a Flink checkpoint or savepoint, each registered Timer in the restored state that was supposed to be fired before restoration will be fired immediately.
- Timers can be deleted.
As of Flink 1.6, Timers can be paused and deleted. If you are using a version of Apache Flink older than Flink 1.5 you might be experiencing a bad checkpointing performance due to having many Timers that cannot be deleted or stopped.
对应源码
InternalTimerService.class
//触发event timer检测 public void advanceWatermark(long time) throws Exception { currentWatermark = time; InternalTimer<K, N> timer; while ((timer = eventTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) { //所有的小于当前watermark时间的Timer全部触发 eventTimeTimersQueue.poll(); keyContext.setCurrentKey(timer.getKey()); triggerTarget.onEventTime(timer); } }
@Override //触发proces timer public void onProcessingTime(long time) throws Exception { // null out the timer in case the Triggerable calls registerProcessingTimeTimer() // inside the callback. nextTimer = null; InternalTimer<K, N> timer; while ((timer = processingTimeTimersQueue.peek()) != null && timer.getTimestamp() <= time) { //队列中小于等于当前时间的Timer全部触发 processingTimeTimersQueue.poll(); keyContext.setCurrentKey(timer.getKey()); triggerTarget.onProcessingTime(timer); } if (timer != null && nextTimer == null) { //如果队列还有Timer不为空,则向系统定时器注册下一个 //下面会看到,每一次注册Timer只是加入queue,只有最近要触发的才会注册到系统的定时器 nextTimer = processingTimeService.registerTimer(timer.getTimestamp(), this); } }
源码注册event timer是直接加入到queue中,注册process会稍微复杂。
@Override public void registerProcessingTimeTimer(N namespace, long time) { InternalTimer<K, N> oldHead = processingTimeTimersQueue.peek(); if (processingTimeTimersQueue.add(new TimerHeapInternalTimer<>(time, (K) keyContext.getCurrentKey(), namespace))) { //队列中有注册过timer,则下一次得到下一次触发时间,否则返回long最大值 long nextTriggerTime = oldHead != null ? oldHead.getTimestamp() : Long.MAX_VALUE; // check if we need to re-schedule our timer to earlier if (time < nextTriggerTime) { //当前注册的time小于之前注册过的time,或者之前没有注册过 if (nextTimer != null) { //之前注册过,但是这次注册时间更早,要先触发这个 //取消之前注册的,使用新时间注册,将时间提前 nextTimer.cancel(false); } //注册这个time nextTimer = processingTimeService.registerTimer(time, this); } //time >= nextTriggerTime的,只是加到队列了,但是没有注册。也就不会触发 //加到队列中的时间,会在上一次触发后,从队列中取出下一次要触发的注册,不会一次注册所有队列中的时间,应该是为了防止一个时间注册多次吧。 } }
每个window都有自己的TriggerContext实例,也就有自己独立的Timer队列,这个具体的window实例是
WindowOperator<K, IN, ACC, OUT, W extends Window>类。Process time的实现机制
在源码
SystemProcessingTimeService中,可以看到,注册的processTimer是通过scheduledThreadPoolExecutor去实现的,通过java jdk自带的线程库在指定的时间执行,但是如果GC等造成调用延迟了,传入OnProcessEventTime的时间还是之前注册的时间。processingTimeTimer的触发则是在onProcessingTime方法中(SystemProcessingTimeService的TriggerTask及RepeatedTriggerTask的定时任务会回调ProcessingTimeCallback的onProcessingTime方法),它会移除timestamp小于等于指定time的processingTimeTimer,然后回调triggerTarget.onProcessingTime方法
Event time的实现机制
eventTimerTimer的触发主要是在advanceWatermark方法中(
AbstractStreamOperator的processWatermark方法会调用InternalTimeServiceManager的advanceWatermark方法,而该方法调用的是InternalTimerServiceImpl的advanceWatermark方法),它会移除timestamp小于等于指定time的eventTimerTimer,然后回调triggerTarget.onEventTime方法;